preview_ready
생성이 끝나면 여기에 미리보기 요약이 나타납니다.
언어 제안
스캔 PDF를 EPUB으로, 막연한 변환 없이
스캔 PDF 한 권을 업로드하고, 앞 10페이지에서 실제 EPUB 미리보기를 만든 뒤, 전체 변환에 더 시간을 쓰기 전에 이 원본이 가치가 있는지 먼저 판단할 수 있습니다.
Direct answer
A scanned PDF to EPUB converter turns an image-based PDF book into a reflowable EPUB. Scanned PDF to EPUB focuses on a preview-first path: upload one PDF, generate an EPUB preview from the first 10 pages, then check OCR and layout risk before a full-book conversion.
스캔 PDF 한 개를 올리고 앞 10페이지를 EPUB으로 확인한 뒤, 가치가 없으면 일찍 멈출 수 있습니다.
데모 사용
이 로컬 데모는 앞 10페이지까지만 처리합니다. 제목, 줄바꿈, 수식이 여전히 깨져 있으면 더 큰 변환 작업 전에 여기서 멈출 수 있습니다.
미리보기 상태
처리 중
위에서 PDF를 업로드하면 미리보기 흐름이 시작됩니다.
미리보기 페이지
0
OCR 사용 페이지
0
검토 필요
0
preview_ready
생성이 끝나면 여기에 미리보기 요약이 나타납니다.
페이지 내 미리보기
여기서 먼저 몇 페이지를 확인한 뒤, 읽을 만하면 EPUB을 다운로드하세요.
대부분의 사용자는 위 PDF 업로드부터 시작하면 됩니다. 변환 전에 추출 텍스트를 줄 단위로 보고 싶을 때만 여세요.
단일 추출 페이지를 손으로 확인하고 싶을 때만 사용하세요. 주요 경로는 여전히 위 PDF 업로드입니다.
전체 점수
55/100
발견된 문제
3
검토 필요
2
치명적
0
깨진 하이픈
깨진 하이픈이 감지되었습니다.
수식 구조 위험
수식처럼 보이는 텍스트가 감지되었습니다. 렌더링 전략을 확인하세요.
페이지 번호 잔존
마지막 줄이 페이지 번호처럼 보입니다.
현재 제품은 전체 출판 파이프라인이 아닙니다. 먼저 답하는 질문은 하나입니다. 이 스캔 PDF가 추가 시간을 낭비하지 않고 읽을 만한 EPUB이 될 수 있는가.
1
스캔 PDF를 하나 선택하고 앞부분에서 짧은 EPUB 미리보기를 생성합니다.
2
미리보기를 열어 줄바꿈, 제목, 수식, 캡션이 여전히 읽기 좋은지 확인합니다.
3
전체 변환으로 진행할지, 원본을 손볼지, 나쁜 스캔에 더 시간을 쓰기 전에 멈출지 결정합니다.
독자들이 계속 부딪히는 문제
Reddit, Calibre 스레드, 전자책 포럼에서 스캔본 독자들은 비슷한 불만을 계속 말합니다. 이 미리보기는 전체 변환 전에 그 문제에 먼저 답하기 위해 존재합니다.
01
많은 스캔 PDF는 사실상 페이지 사진일 뿐입니다. 쓸만한 텍스트 레이어가 없으면 변환기는 멈추거나 파일이 비대해지거나 각 페이지를 이미지로 넣어 버립니다.
02
숨겨진 OCR 레이어에는 깨진 하이픈, 잘못된 따옴표, 잡기호, 리플로우에서 무너지는 줄바꿈이 자주 남아 있습니다.
03
학술 논문과 오래된 저널은 읽기 순서가 쉽게 틀어집니다. 다단, 수식, 그림 캡션이 특히 신뢰를 깨는 지점입니다.
04
PDF가 열리더라도 작은 화면에서는 확대, 이동, 자르기, 반복이 됩니다. 사용자가 알고 싶은 것은 리플로우 후 정말 읽을 만한지입니다.
이 예시들은 문구만으로 전달되지 않는 것을 보여 줍니다. 변환 전 스캔 PDF가 어떤 모습인지, 믿을 수 있는 EPUB 미리보기가 무엇을 지켜야 하는지입니다.

Use Case 1
This is the simplest but highest-volume use case: judge whether a yellowed chapter scan becomes comfortable enough to read on a small e-reader.

Use Case 2
Formula pages break trust fast. A useful preview proves that equations, theorem blocks, and surrounding explanation still make sense on a real reading device.
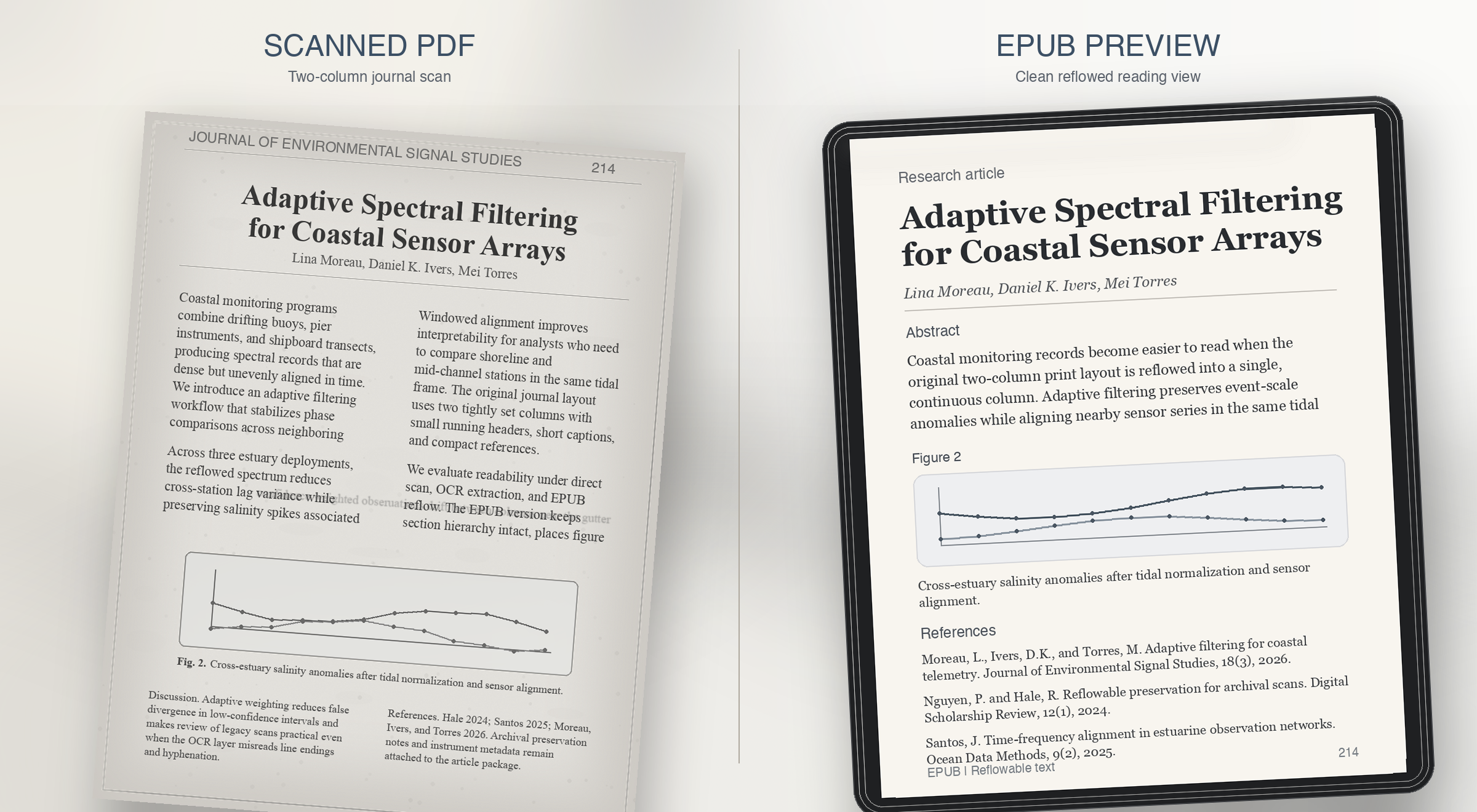
Use Case 3
Research journals usually fail on reading order. The preview should prove that columns, captions, and references survive reflow instead of collapsing together.

Use Case 4
Some PDFs have no usable text layer at all. The right behavior is not fake confidence, but a preview that shows what OCR recovered and what still needs review.
The live checker runs the repo's quality rules against extracted page text. It flags empty OCR output, page-number leaks, broken hyphenation, bad spacing, and formula-structure risk.
The current demo can generate a preview EPUB directly from an uploaded PDF. Production-grade full-book conversion still needs stronger layout recovery, better OCR repair, EPUB validation, and job orchestration.
In this demo, the PDF is uploaded to the current preview service so it can generate a sample EPUB. Review your deployment and privacy settings before testing private material. The page checker still exists for users who want to inspect extracted text before uploading.
The wedge is scanned PDF input, extracted page text for diagnosis, and a reflowable EPUB preview for reading on Kindle- and Kobo-style devices. It is not trying to become a broad everything-to-everything converter.
Accurate enough to judge reading comfort and obvious structural damage. The preview is meant to answer whether the book feels clean enough to continue, not to replace final editorial review for every edge case.
Some cleanup can be automated, but the product should stay honest about uncertainty. The key promise is to surface where review is needed so the user can decide whether to repair, crop, rerun OCR, or stop.
Those are the pages most likely to trigger risk labels. Formula structure, tabular alignment, footnotes, and badly cropped scans often need targeted repair before an EPUB is truly comfortable to read.
Readers and document owners with scanned books, academic PDFs, or public-domain material who want a reflowable EPUB for Kindle or Kobo without proofreading every page manually.
Generic converters export files, but they rarely explain where OCR or layout recovery failed. This product is designed to show risk before the user commits to a full conversion.
Yes. The main demo flow is designed around that exact question: upload one PDF, inspect the first pages, review OCR risk, and judge whether the full book is worth converting.
The most useful examples are before-and-after comparisons for noisy OCR, math-heavy academic pages, two-column journal layouts, footnotes, captions, and image-only scans that need OCR fallback.
It should prove reading comfort, not just file export. A good preview shows whether line breaks, page numbers, formulas, headings, columns, and captions still make sense on a small reading device.
PDF 업로드나 페이지 점검을 몇 초 안에 시작할 수 있습니다. 데모에는 가입이 필요 없습니다. 저장된 미리보기나 이후 전체 변환이 필요할 때만 원타임 액세스를 사용하세요.
원타임 액세스
비밀번호 대신 이메일 원타임 코드를 사용하세요. 전체 변환, 저장된 미리보기 기록, 검토 대기열 안내를 받을 수 있습니다.
원타임 액세스
Saved previews
Sign in with a one-time code to save previews and reopen them later.