预览已就绪
生成完成后,这里会显示预览摘要。
语言建议
扫描 PDF 转 EPUB,不再盲转
上传一本扫描版 PDF,先生成前 10 页的真实 EPUB 预览,再决定这份源文件值不值得继续做完整转换。
直接答案
扫描 PDF 转 EPUB 转换器会把图片型 PDF 图书变成可重排阅读的 EPUB。Scanned PDF to EPUB 采用先预览再转换的路径:上传一份 PDF,先生成前 10 页 EPUB 预览,再检查 OCR 和版面风险,最后决定是否继续整本转换。
上传一份扫描 PDF,先看前 10 页 EPUB 效果,不值得继续就立刻停。
立即试用
当前预览流程只处理前 10 页。如果标题、断行或公式仍然很乱,你可以在这里直接止损。
预览状态
处理中
上传一个 PDF,即可开始预览流程。
预览页数
0
OCR 页数
0
待复查
0
预览已就绪
生成完成后,这里会显示预览摘要。
页内预览
先在这里看前几页预览,如果阅读效果可以,再下载 EPUB。
大多数用户直接从上面的 PDF 上传开始。只有在你想逐行检查抽取文本时,再展开这里。
只有当你需要手动检查单页抽取结果时才用这里。主流程仍然是上面的 PDF 上传。
总分
55/100
发现问题
3
待复查
2
严重
0
断词错误
检测到断词错误。
公式结构风险
检测到类似公式的内容,请检查渲染策略。
页码残留
最后一行看起来像页码。
现在这个产品不是完整出版流水线,它先回答一个问题:这份扫描 PDF 值不值得继续投入时间去做成可读 EPUB?
1
选择一份扫描 PDF,先生成前几页的短 EPUB 预览。
2
打开预览,检查断行、标题、公式和图注在真实阅读场景里是否还清晰可读。
3
决定继续整本转换、先修源文件,还是尽早停止,不再把时间浪费在糟糕扫描上。
用户反复遇到的问题
无论是 Calibre 讨论区、Reddit,还是 e-reader 论坛,扫描书转换的痛点基本都集中在这几件事。这个预览页就是为了先把这些问题看清。
01
很多扫描 PDF 本质上只是页面照片。没有可用文字层时,转换器要么卡住,要么把每页当图片塞进 EPUB。
02
隐藏的 OCR 文字层经常带着断词、引号错误、奇怪符号和糟糕断行,搜索能用,阅读却很差。
03
学术论文和旧期刊最容易在阅读顺序上出问题,公式、图注和参考文献也最容易失真。
04
很多文件即使能打开,也会变成不断缩放、平移、裁边。用户真正想知道的是:重排之后到底能不能读。
这些样例比文案更有说服力:它们直接展示不同类型的扫描 PDF 在转换前是什么样,以及一个可信的 EPUB 预览应该保住哪些阅读结构。

Use Case 1
This is the simplest but highest-volume use case: judge whether a yellowed chapter scan becomes comfortable enough to read on a small e-reader.

Use Case 2
Formula pages break trust fast. A useful preview proves that equations, theorem blocks, and surrounding explanation still make sense on a real reading device.
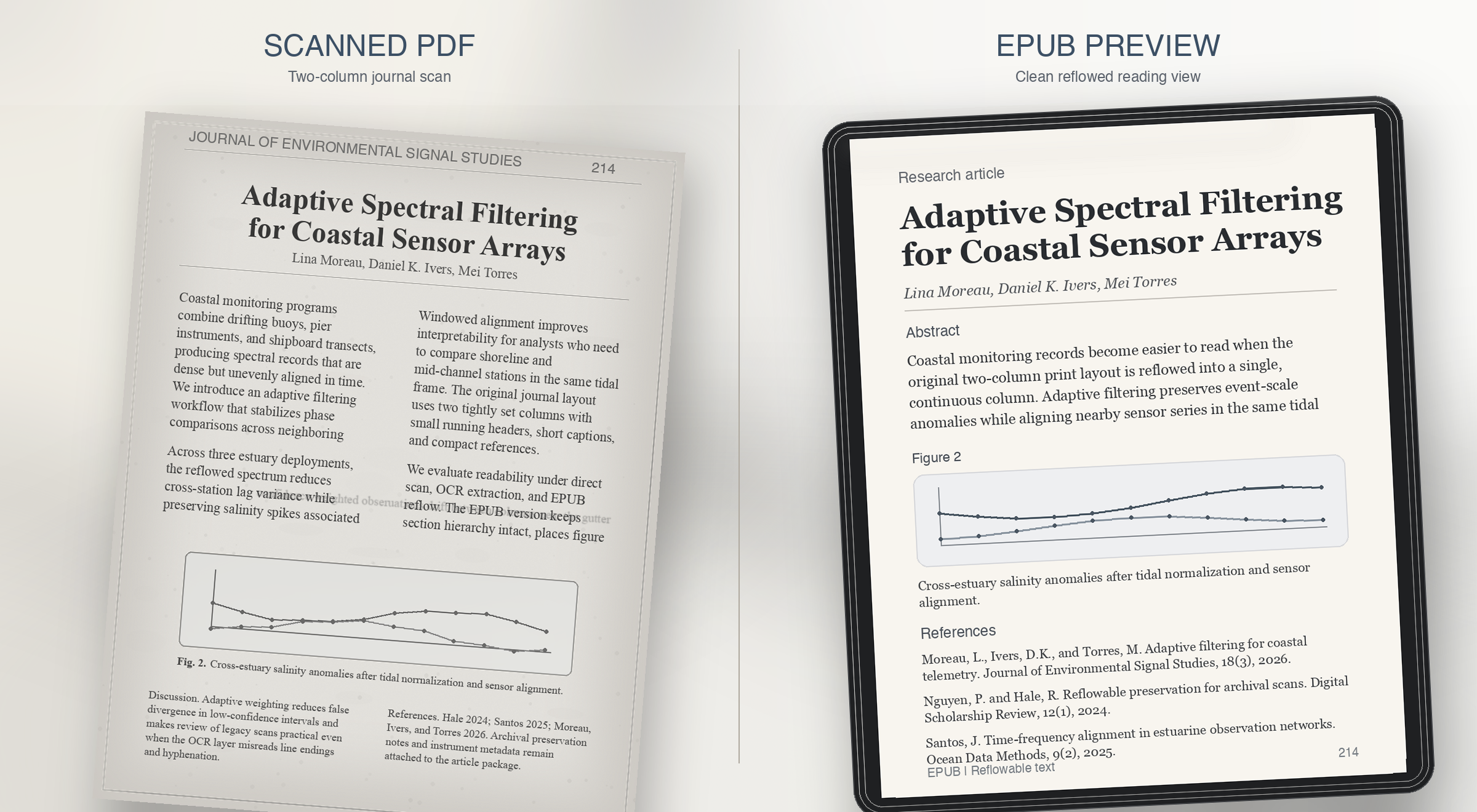
Use Case 3
Research journals usually fail on reading order. The preview should prove that columns, captions, and references survive reflow instead of collapsing together.

Use Case 4
Some PDFs have no usable text layer at all. The right behavior is not fake confidence, but a preview that shows what OCR recovered and what still needs review.
The live checker runs the repo's quality rules against extracted page text. It flags empty OCR output, page-number leaks, broken hyphenation, bad spacing, and formula-structure risk.
The current demo can generate a preview EPUB directly from an uploaded PDF. Production-grade full-book conversion still needs stronger layout recovery, better OCR repair, EPUB validation, and job orchestration.
In this demo, the PDF is uploaded to the current preview service so it can generate a sample EPUB. Review your deployment and privacy settings before testing private material. The page checker still exists for users who want to inspect extracted text before uploading.
The wedge is scanned PDF input, extracted page text for diagnosis, and a reflowable EPUB preview for reading on Kindle- and Kobo-style devices. It is not trying to become a broad everything-to-everything converter.
Accurate enough to judge reading comfort and obvious structural damage. The preview is meant to answer whether the book feels clean enough to continue, not to replace final editorial review for every edge case.
Some cleanup can be automated, but the product should stay honest about uncertainty. The key promise is to surface where review is needed so the user can decide whether to repair, crop, rerun OCR, or stop.
Those are the pages most likely to trigger risk labels. Formula structure, tabular alignment, footnotes, and badly cropped scans often need targeted repair before an EPUB is truly comfortable to read.
Readers and document owners with scanned books, academic PDFs, or public-domain material who want a reflowable EPUB for Kindle or Kobo without proofreading every page manually.
Generic converters export files, but they rarely explain where OCR or layout recovery failed. This product is designed to show risk before the user commits to a full conversion.
Yes. The main demo flow is designed around that exact question: upload one PDF, inspect the first pages, review OCR risk, and judge whether the full book is worth converting.
The most useful examples are before-and-after comparisons for noisy OCR, math-heavy academic pages, two-column journal layouts, footnotes, captions, and image-only scans that need OCR fallback.
It should prove reading comfort, not just file export. A good preview shows whether line breaks, page numbers, formulas, headings, columns, and captions still make sense on a small reading device.
先上传 PDF 或跑一次页面检测。demo 无需注册;需要保存记录和后续整本转换时,再用一次性登录进入。
一次性登录
不用密码,直接用邮箱一次性验证码登录。后续可保存预览记录、排队整本转换、管理待复查页面。
一次性登录
保存的预览
使用一次性验证码登录后,才能保存预览并再次打开。